「king − man + woman = queen」って数式、AIが本当に解いてるんですか?
フッ、その式は私が独自に発見し、AAAIで発表予定だ。
御託さん、それ 30年前に Mikolov 氏が論文で出されています わよ。
……。

- 埋め込み(Embedding) とは、トークン(単語の塊)に 意味の「住所」を与える仕組み。一語一語を空間の中の1点として置き直す。
- これで 意味の近さが「距離の近さ」になる。似た言葉ほど近くに集まるので、機械が言葉の意味を扱えるようになる(変換のしくみは本文で)。
- イメージは 意味の地図上の住所。同じ町内に仲間が住み、地図上の方向が「性別」「複数形」などの意味のちがいを表す。
「ChatGPT は単語をどう扱っているのか?」と聞かれて、「いや、文字列でしょ?」と答えてしまうと、その先の Attention も MLP もすべて意味不明になる。LLM は文字列を直接扱わない。最初にやるのは、トークンを ベクトル(数のリスト)に変換すること だ。
これが 埋め込み(Embedding) と呼ばれる仕組みで、Transformer の入口にあたる。本記事は、なぜ単語をベクトルにするのか、ベクトルになるとなぜ「意味の演算」ができてしまうのか、そこに焦点を絞る。
なぜ文字列をそのまま使えないのか

機械学習モデルが扱える入力は、突き詰めれば 数の配列だけ。掛け算と足し算ができないと学習できない。
「king」という文字列を入れて「queen」という文字列を出すモデル、というイメージは数学的には成立しない。何らかの形で 数値表現に落とす 必要がある。
最も素朴な方法は、辞書順で 1番目の単語に 1、2番目に 2、…と番号を振ることだ(整数 ID)。だが、これだと 「1と2が近い意味」「3はその2倍」 という意味のない関係が紛れ込む。「apple = 1, banana = 2, zebra = 50,000」と振ったとして、apple と banana が近いとは限らないし、zebra が 50,000倍重要なわけでもない。
数を1つだけ割り当てると、意味的な近さを表現する余地がない。じゃあどうするか — 数を1つじゃなく、数百〜数千個割り当てる しかない。
埋め込み = トークンをベクトルにする
埋め込みのしていることは、本質的にこれだけだ。
トークン1つ ↔ 数のリスト(=ベクトル)1本
GPT-3 の場合、1つのトークンに 12,288個の数 が割り当てられる。「king」は12,288次元のベクトル、「queen」も別の12,288次元のベクトル、「apple」もまた別の…という具合。
この対応関係を保管しているのが 埋め込み行列 W_e だ。これは「語彙数 × 埋め込み次元」のテーブルになっていて、GPT-3 では「50,257トークン × 12,288次元」の行列。重みパラメーターの数はこれだけで 約6.17億個。モデル全体の1,750億のうち、けっこうな部分が「ただの単語→ベクトル変換表」に使われている。
「方向」が「意味」になる
ここからが面白い。学習が進むと、空間の方向が意味と結びつく。
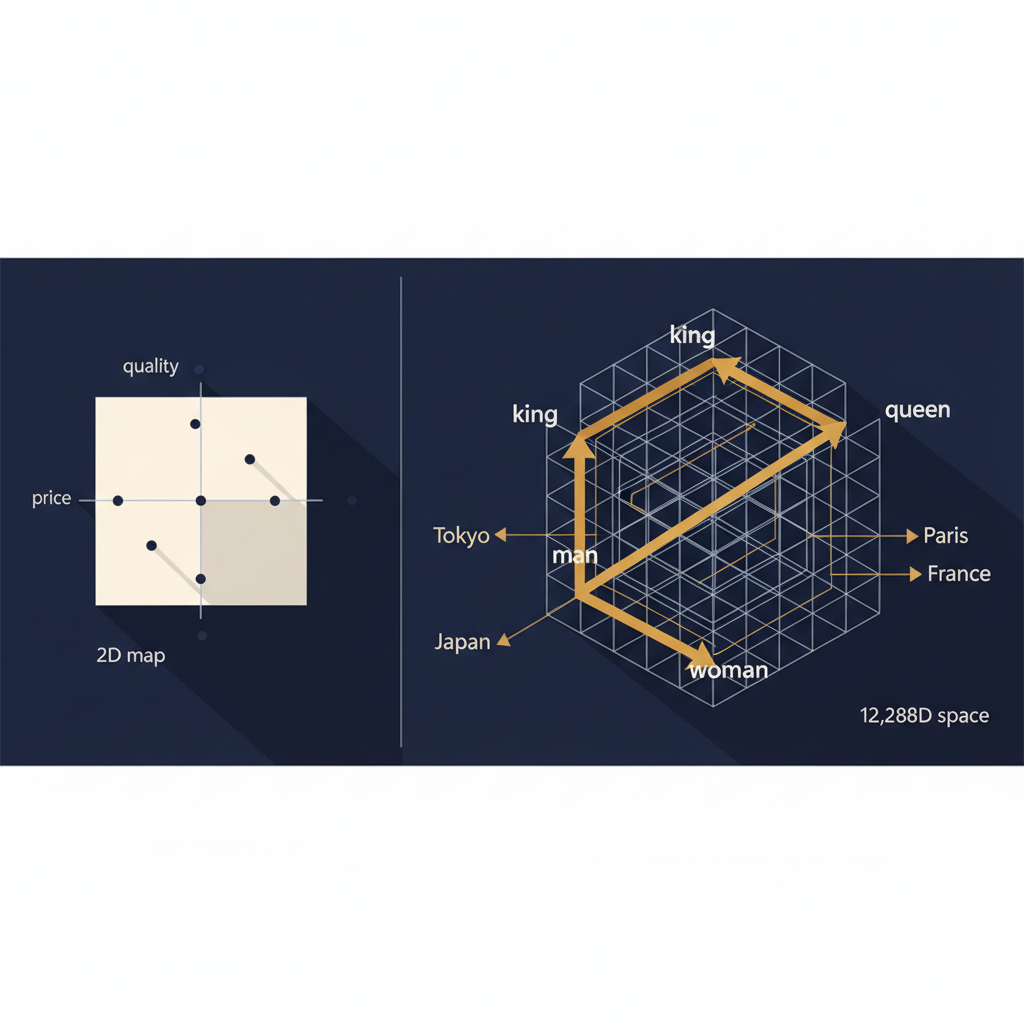
コンサル流に置き換えると分かりやすい。我々がいつもパワポで描く「2軸マップ」を思い出してほしい。横軸が「価格」、縦軸が「品質」、点をプロットして「うちはここ、競合はここ」とやるアレだ。あれは 2次元の埋め込み に他ならない。
埋め込みでやっているのも本質的に同じ。ただし軸の数が 12,288本ある。そして人間が「価格」「品質」と決めたわけではなく、学習が勝手に有用な軸を見つける。
たとえば学習後の埋め込み空間には、こんな方向が自然に現れる。
- ある方向に動くと「性別」が変わる(king ↔ queen)
- 別の方向に動くと「単数→複数」になる(cat ↔ cats)
- また別の方向に動くと「国名→首都」になる(Japan → Tokyo)
これらの方向は、人間が手で指定したものではない。「次の単語を予測する」という1つのタスクを延々と訓練しているうちに、勝手にこういう構造が立ち上がる。
教科書的な例: king − man + woman ≈ queen
伝統的な例として、ベクトル演算で意味の操作ができることを示すのがこれ。
vec(king) − vec(man) + vec(woman) ≈ vec(queen)
「king」のベクトルから「男性」の方向ぶんを引き、「女性」の方向ぶんを足すと、埋め込み空間の中で「queen」のベクトルにとても近い場所 にたどり着く。
つまり「性別の方向」が空間内に確かに存在する、ということだ。これがあると、モデルは「未知の女性版の単語」を求めるとき、近い領域を探すだけで答えを出せる。
似た例:
vec(Tokyo) − vec(Japan) + vec(France) ≈ vec(Paris) vec(walking) − vec(walked) + vec(swam) ≈ vec(swimming)
「首都の方向」「過去形→現在進行形の方向」が、空間に埋め込まれているということ。
ベンチマークもベクトルの近さで測れる
コンサル業務にもう一歩寄せる。クライアントの「類似事例検索」を考えてみよう。
従来のやり方は、業界・売上規模・地域などのタグで絞り込んで「条件マッチ」する案件を引っ張る。だが、本当に欲しいのは「雰囲気が近い案件」だ。
埋め込みがあると、それぞれの案件記述をベクトル化して、新しい案件のベクトルとの 内積(類似度)が高い順 に並べるだけで済む。「業種は違うけど構造は近い」「規模は違うけど論点は同じ」みたいな、人間が直感でやっていた類似探索が 数値計算で再現できる。
これが Transformer 以前から「Word2Vec」「BERT」などで実用化されていた応用だ。Transformer の埋め込みも本質的に同じ仕組みを継承している。
フッ、要するにこれは4P分析の高次元版だな。Product, Price, Place, Promotion …で、たった4軸だぞ?マッキンゼーの友人に言わせれば、本質はそこではないがな。
いや、御託さん、これ12,288軸ですよ。我々がパワポで描いてる2軸マップが、6,000枚分くらい同時に走ってるイメージで…広告時代に学んだことなんですが、「ポジショニング」って結局これですよね。本来のコンサルとしては、押さえておかないと…
あら…私の経験では、Excelの列ベクトルで十分ですわよ、ええ。12,288列のシート、INDEX/MATCH で参照できますし。
えっと…つまり、king − man + woman = queen って、社員 − 部長 + パートナー = 取締役、みたいな感じで…(無言で計算しはじめる)
何次元あれば十分なのか
「12,288次元って多すぎでは?」と思うかもしれない。実際これは設計判断で、モデルによって違う。
- Word2Vec(2013年): 300次元
- BERT-base(2018年): 768次元
- GPT-2: 1,600次元
- GPT-3: 12,288次元
- GPT-4: 非公開(おそらく1万を超える)
なぜ次元を増やすかというと、多くの軸を持つほど多くの意味を独立に表現できる から。低次元だと「性別」の方向と「単複」の方向が混ざって、片方を動かすと意図せず他方も動いてしまう。次元が増えれば、軸を直交に近く配置して 意味同士の干渉を減らせる。
逆に多すぎると、計算コストが爆発する(後段の行列が全部 12,288 ベースになるため)。実用上は「次のトークン予測の精度が頭打ちになる手前」あたりに設定する。
なぜ Transformer の出発点として重要か
Transformer の中で起きていることは、ざっくり言うと「埋め込みベクトルを文脈に応じて何度も書き換える」プロセスだ。
入口で「king」がベクトルになる。アテンション層を通ると、周りの単語(「the」「Macbeth」「kill」など)の情報が混ざり、「king」のベクトルが「シェイクスピアの戯曲のスコットランド王」を指す方向に動く。MLP 層を通ると、また別の方向に変換される。
こうして 同じトークンが、文脈次第で異なるベクトル位置を持つ ようになる。これが Transformer の表現力の核心だ。
つまり埋め込みは「Transformer が動き出す前のスタート位置」を決めている。スタート位置がよく学習されているから、その後のアテンションと MLP が活きてくる。
なるほど、これは産業革命だ。…で、具体的に何次元にすればいいんだっけ?ふわっとした方向感としては、まず1万次元で行ってみるか?これパワポにしてみる?
部長、次元数はモデル設計の最適化で決まるので、ふわっとは決められないんですけど…
フッ、本質はそこではない。私の友人の MBA 仲間も言っていたが、結局重要なのは「次元呪い」だ。サンデルの本にもあるように、人間の認知は3次元で…
あら、御託さんのおっしゃる「次元呪い」って、どの本ですの?私の経験では、そういう専門用語はちゃんと出典を…
…(沈黙)
あの…ぼく、社内のCRM の取引先データ全部ベクトル化してみたんですけど、業界タグだけで分類してた頃より、ずっと「似てる案件」が出てきます…(無言でデモ画面を開く)
